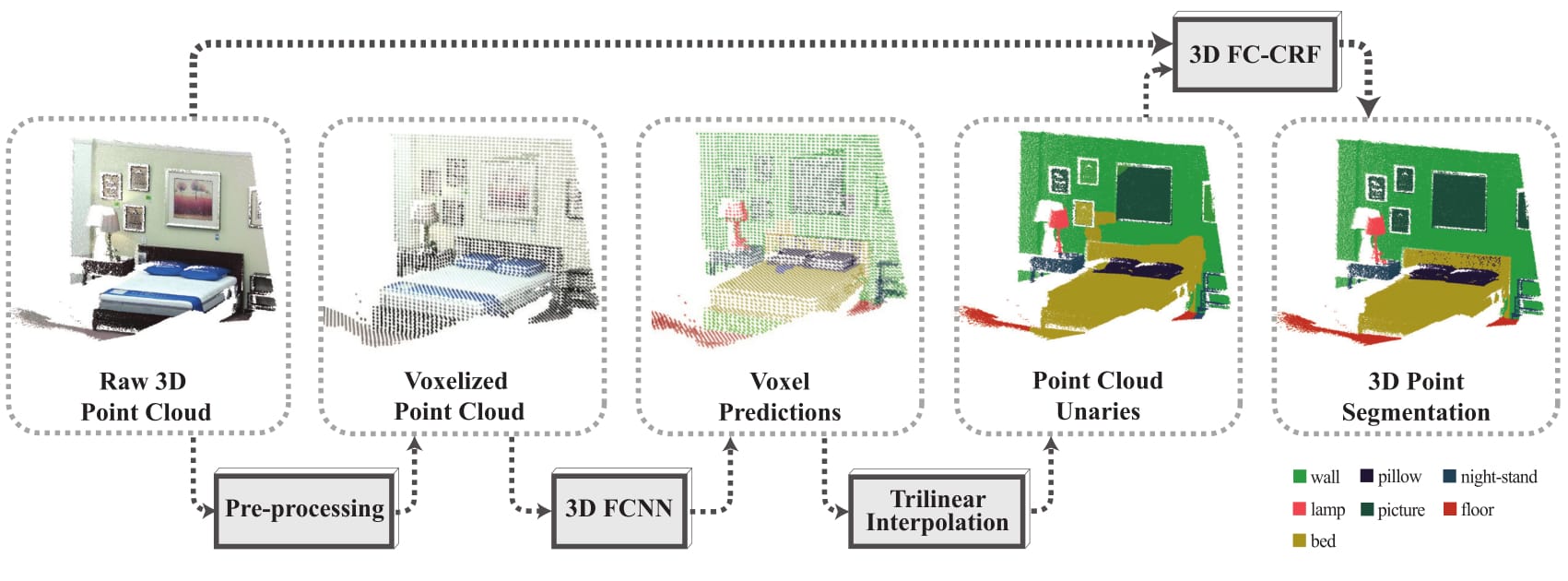
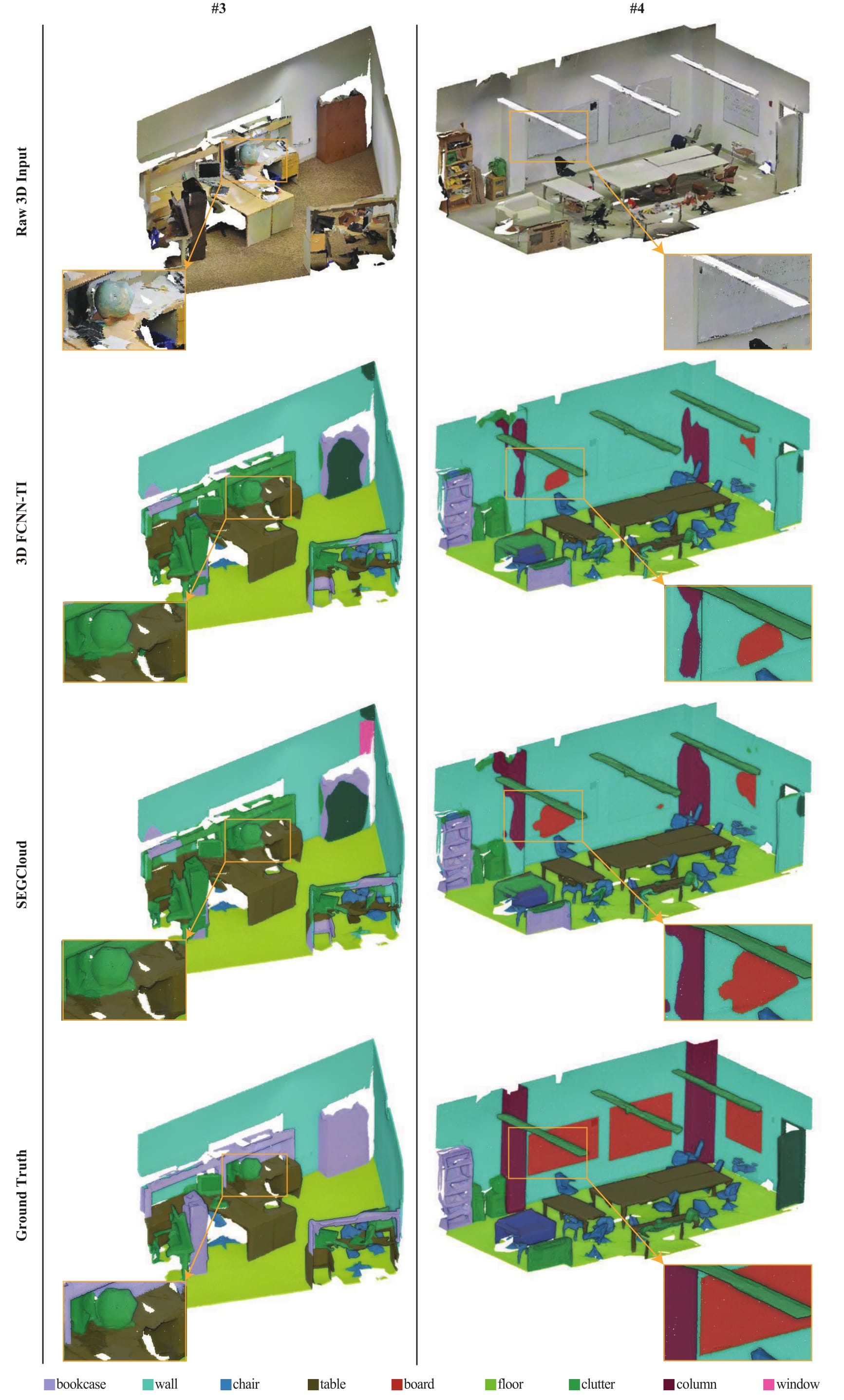
SEGCloud: Semantic Segmentation of 3D Point Clouds
|
|
|
|
|
|
|
(Spotlight)